

GetApp offers objective, independent research and verified user reviews. We may earn a referral fee when you visit a vendor through our links.
Our commitment
Independent research methodology
Our researchers use a mix of verified reviews, independent research, and objective methodologies to bring you selection and ranking information you can trust. While we may earn a referral fee when you visit a provider through our links or speak to an advisor, this has no influence on our research or methodology.
Verified user reviews
GetApp maintains a proprietary database of millions of in-depth, verified user reviews across thousands of products in hundreds of software categories. Our data scientists apply advanced modeling techniques to identify key insights about products based on those reviews. We may also share aggregated ratings and select excerpts from those reviews throughout our site.
Our human moderators verify that reviewers are real people and that reviews are authentic. They use leading tech to analyze text quality and to detect plagiarism and generative AI.
How GetApp ensures transparency
GetApp lists all providers across its website—not just those that pay us—so that users can make informed purchase decisions. GetApp is free for users. Software providers pay us for sponsored profiles to receive web traffic and sales opportunities. Sponsored profiles include a link-out icon that takes users to the provider’s website.
How to Select Data Classification Levels for Your Business
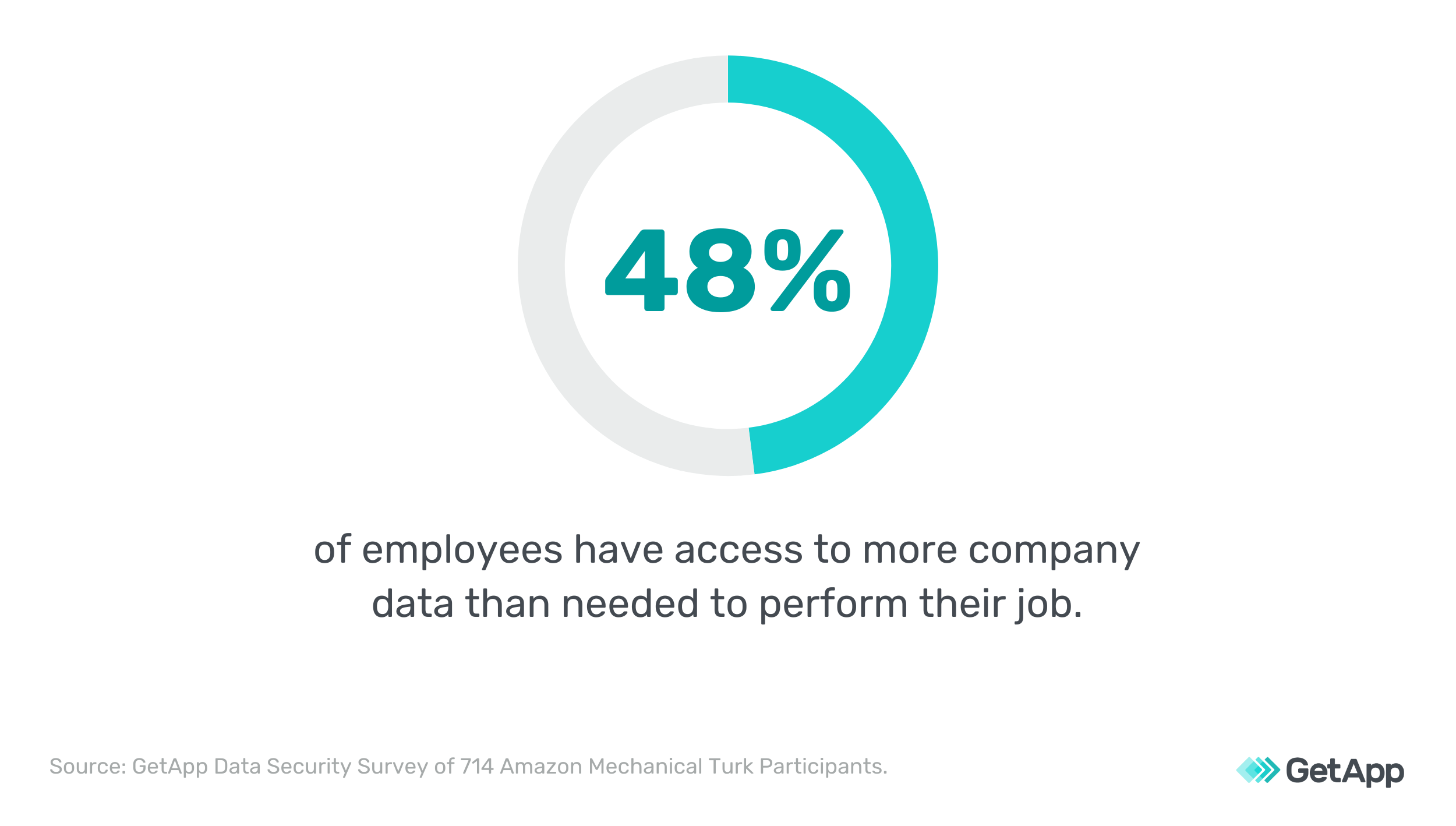
A recent GetApp survey found that 48% of businesses allow employees to access more data than necessary. 12% reported that employees have access to all company data.

Classifying data simplifies data security efforts and ensures that your employees know what information can be made public and what should stay internal.
However, a recent GetApp survey found that nearly half of all businesses allow employees to access more data than is necessary for their jobs. In fact, 12% of businesses reported that employees have access to all company data.
A data classification program makes it easier to restrict data to only those who need it, thereby reducing unwanted exposure-a concept known as the principle of least privilege.
Why is a data classification policy important?
Banks don’t give every employee the keys to the vault, so why would you let every employee access your organization’s most precious data?
Data classification policies help distinguish between information of varying sensitivity levels, thereby allowing you to identify and invest in securing the more sensitive information. Other reasons to have a data classification policy include:
Helps organize and track critical business data: 80% of companies don't know where their sensitive data is located and how it moves across the network. With a data classification policy you can assign employees responsibility for its protection. It also helps you plan actions to contain potential data leaks.
Supports optimal use of resources, reducing costs: Enforcing data controls requires you to spend time and money on tools such as identity and access management (IAM) and data loss prevention (DLP). By determining the criticality of different types of data, you can better focus on data that must be protected at all costs without wasting resources on non- or less-critical data.
Employees become aware and conscious of data security: Having a formal data classification policy that is accessible to employees makes them consciously aware of how they handle business data. Employees tend to make more secure choices while storing or transmitting data when they are aware they are working on sensitive information.
Makes it easier to comply with regulatory mandates: Regulatory frameworks such as HIPAA, PCI , and GDPR mandate businesses to protect sensitive data such as health records, payment data, or personally identifiable information (PII). Businesses must take care to classify such data as confidential or restricted to ensure that they are not disclosed without authorization or stored or transmitted through unencrypted channels.
Which data classification levels should you use?
There are endless ways to classify your data, but most organizations categorize or bucket data as variations of public, private, and confidential.
To get an idea of which labels are used most often, GetApp’s recent data security survey asked respondents about the categories used at their companies. The results are as follows:

Pro tip
Keep data classification levels limited; three or four levels work best. Too many categories burden employees and often lead to misclassification and noncompliance.
4 steps for building a data classification policy
The classification levels you select form the foundation of your data classification policy. Here are four practical steps to creating a policy that best suits your business.
1. Connect with management across the business
Business leaders and management at all levels know best the different kinds of data they handle. They may also be following unwritten data policies that dictate who can access or edit different information.
Connecting with the different teams also helps to identify duplicated and unclassified legacy data, take different business contexts into account, and create a unified data classification policy.
2. Identify regulatory and legal risks
Some kinds of information (such as customer payment information and government identification numbers) are earmarked as more sensitive by regulatory bodies and need to be strongly secured.
For example, GDPR considers genetic or biometric data, a person’s ethnic or racial status, and data on their health conditions to be sensitive personal data. Any unauthorized exposure or breach of sensitive personal data is fined by the regulatory body. You need to identify such sensitive information and ensure that it is adequately protected using strong authentication and encryption methods.
3. Frame data levels and policies around business risk
Define your data classification levels based on the value of the different data types and the business risk their exposure may cause. Some of the key questions to ask to determine and value/risk of your data are:
Criticality: How important is the data for everyday operations and business continuity?
Availability: Is timely and reliable access to the data important for your business?
Sensitivity: What is the potential impact on the business if the data is compromised?
Integrity: How important is it to ensure that the data is not tampered with during storage or while in transit?
Retainability: How long must you retain the data according to regulatory requirements or industry standards?
Based on the above parameters if you find the value or business risk of the data type to be high, it is important that you classify it as sensitive.
4. Operationalize your data classification policy
Here are some ways to implement your data classification policy throughout the business.
Train employees on the need to classify data for improved privacy and security: Create awareness about your policy and make documents available to all your employees. Schedule training sessions that teach them to distinguish between the different data they use and the policies applicable to each type. Another way to promote your data classification initiative is to recognize/reward employees who help identify violations or discrepancies in your data protection policy.
Embed data classification levels into business workflows to lower the burden on employees: Use strategies such as watermarks, automated data tagging and labeling, or restricted access to sensitive data to enforce your data classification policy. This helps reduce users' burden of identifying the category the data belongs to and how to use it.
Review and monitor the effectiveness of your data classification policy: Establish a process to review your data classification policy and monitor adherence. Track policy violations and attempt to understand their causes. Incorporate changes to your data classification scheme based on employee feedback, regulatory changes, or any contractual requirements.
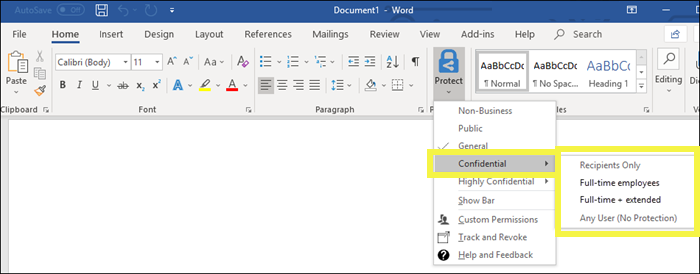
Sensitivity labels in Microsoft Word (Source)
Implement data-access strategies to minimize risk
The following technology strategies will help improve your overall security posture and prevent employees from inadvertently spilling business secrets.
Employ network segmentation: Network segmentation strategy separates networks holding different types of data and stops hosts from communicating unnecessarily. This way, a hacker with access to a compromised device on one network can't tunnel their way over to sensitive data hosted on another.
Reduce privileged administrator accounts: Provide only a few trusted employees with administrative rights to view, edit, or delete confidential business files. Monitor these privileged accounts closely to check if they're misused, exploited, or subjected to malware attacks.
Restrict sharing: Endpoint security solutions can ensure that a document labeled sensitive is not copied to third-party web apps or removable storage devices such as USB drives. You can also configure your email security options to restrict employees from sending business data to personal accounts.
Improve access controls: Enforce strong access controls, such as multifactor authentication and biometrics, for access to confidential or restricted data. Use a cloud access security broker (CASB) to prevent data exfiltration to unauthorized cloud services. Enable network access restrictions to close unnecessary ports.
Encrypt confidential data: Use encryption tools to mask confidential business data (both in-transit and at-rest). This ensures that unauthorized person are not able to decipher it without the key.
Note
The data security survey referenced in this article was conducted by GetApp in June 2019 among 714 respondents who reported full-time employment in the United States.
More on Security


Jul 23, 2024



